이 글은 지난 글
2022.10.14 - [금융공학] - 상관관계가 있는 세 자산이 움직이는 모습은?
상관관계가 있는 세 자산이 움직이는 모습은?
이 글은 2022.09.30 - [금융공학] - 상관관계가 있는 두 자산이 움직이는 모습은? 상관관계가 있는 두 자산이 움직이는 모습은? 이 글은 2022.09.30 - [금융공학] - 상관관계를 보이는 두 자산의 움직임
sine-qua-none.tistory.com
을 실제 주가를 가지고 알아보는 글입니다. 실제 지수와 주가의 종가를 가지고 주가 간 상관계수를 구해보고, 이를 시각화하는 법에 대해 알아보겠습니다.
데이터 준비
○ KOSPI지수, 삼성전자(005930), SK텔레콤(017670), 신한지주(055550), 코덱스 인버스(114800) 종가데이터를 준비합니다.
○ 기간은 2020년 1월 초부터 2022.10.13일까지 준비했습니다(총 687일)
○ 자료는 아래와 같습니다.

목적은, 5개의 지수/종목의 로그수익률의 상관계수를 분석하고 시각화하는 것입니다. 자료 분석을 위해 pandas라는 python 라이브러리를 쓸 예정입니다. pandas는 매트릭스 형태로 주어진 데이터를 분석하는데 강력합니다. 우선 python code를 보죠.
Python Code
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import scipy
import scipy.linalg
import pprint
df_stock = pd.read_excel('stocks.xlsx')
stock_list = df_stock.columns.tolist()
stock_list.remove('Date')
for col in stock_list:
df_stock[col + '_rate'] = np.log(df_stock[col] / df_stock[col].shift(-1))
df_stock = df_stock.dropna()
df_rate = df_stock[[col + '_rate' for col in stock_list]]
print('Rate DataFrame')
pprint.pprint(df_rate.head())
corr_matrix = df_rate.corr()
pd.set_option('display.max_columns', None)
pd.options.display.float_format = '{:.2f}'.format
np.set_printoptions(precision=3)
print('\nCorrelation Matrix')
pprint.pprint(corr_matrix)
corr = corr_matrix.to_numpy()
print('\nCorrelation Matrix(Array version')
pprint.pprint(corr)
L_scipy = scipy.linalg.cholesky(corr, lower=True)
np.set_printoptions(suppress=True)
print('\nCholesky Decomposition')
pprint.pprint(L_scipy)
sns.pairplot(df_rate)
plt.show()
sns.heatmap(corr_matrix, annot=True, cmap='Blues', # Red, Yellow, Blue 색상으로 표시
vmin=-1, vmax=1, )
plt.show()
코드를 찬찬히 살펴보겠습니다.
import pandas as pd○ pandas 는 데이터 분석을 위한 라이브러리입니다. 데이터는 엑셀처럼 행렬 형태의 구조를 가지고 보통 아래 그림과 같은 구조를 가집니다. 이렇게 생긴 python의 자료 형식을 Dataframe이라 합니다.

열(column) 쪽으로는 데이터의 특징이나 요인을 나타내는 features가 자리 잡습니다. 행(row) 쪽으로는 데이터의 index가 있습니다. 데이터 샘플이라 보면 되겠죠.
df_stock = pd.read_excel('stocks.xlsx')○ read_excel 함수를 이용하여 엑셀 파일을 불러들입니다. 이것을 출력해보면 아래와 같습니다.
Date KOSPI SamsungElec SKT Shinhan KODEX inverse
0 2022.10.13 2162.87 55200 48550 34900 5435
1 2022.10.12 2202.47 55800 48750 34950 5345
2 2022.10.11 2192.07 55400 48700 34650 5395
3 2022.10.07 2232.84 56200 50200 35450 5280
4 2022.10.06 2237.86 56300 50500 34700 5260
.. ... ... ... ... ... ...
682 2020.01.08 2151.31 56800 232500 42000 6455
683 2020.01.07 2175.54 55800 233000 42750 6410
684 2020.01.06 2155.07 55500 231500 42100 6480
685 2020.01.03 2176.46 55500 234000 42750 6430
686 2020.01.02 2175.17 55200 234000 42600 6425
[687 rows x 6 columns]첨부한 엑셀파일의 데이터들이 고스란히 불려 들어와 df_stock 변수에 저장됩니다. column은 Date와 5개 종목의 이름입니다. row 쪽으로는 데이터 샘플(날짜에 따른 종가)들이 쌓여 있습니다.
다음 목적은 KOSPI, SamsungElec, SKT, Shinhan, KODEX inverse 들의 일일 로그수익률을 계산해서 새로운 열들을 만들어 저장해 보는 것입니다.
stock_list = df_stock.columns.tolist() # Dataframe의 열들을 list형으로 저장
stock_list.remove('Date') # 열들 중 'Date' 이름은 삭제하여 list를 만듬○ 목적은 df_stock 변수의 열(columns) 중, 종목 이름으로만 이루어진 list형의 변수를 얻기 위함입니다.
○ DataFrame.columns 는 Dataframe의 열을 반환하는 함수입니다. 반환된 자료 형식은 Series라는 형식입니다.
○ tolist() 는 기존 자료 형식을 list 형식으로 바꾸는 함수입니다.
○ remove는 주어진 list에서 원소를 제거할 때 사용합니다. 위의 예에서는 stock_list에서 'Date'라는 원소를 제거한다는 뜻입니다.
결과를 출력해보면
['KOSPI', 'SamsungElec', 'SKT', 'Shinhan', 'KODEX inverse']위와 같이 나오죠.
for col in stock_list: # 종목이름을 for문으로 돌리면서
df_stock[col + '_rate'] = np.log(df_stock[col] / df_stock[col].shift(-1))
# '종목이름_rate' 라는 새로운 열을 생성하여 로그수익률을 추출
df_stock = df_stock.dropna() #df_stock내 N/A 값이 있는 행,열 모두 제거○ 기존 Dataframe에 새로운 열을 추가하고 싶을 때는 df['A'] = a라는 형태로 간단히 할 수 있습니다. A라는 이름의 column이 생기고 a라는 값이 저장됩니다. 위의 예에서는
KOSPI_rate, SamsungElec_rate
등의 이름을 가진 column이 생기는 것이죠.
○ shift(a) 함수는 주어진 Dataframe을 a만큼 아래로 행을 밀어내리는 것입니다. 만일 a가 음수면, 행을 올리는 게 되겠죠. code에 df_stock[col].shift(-1)은 col이라는 이름의 열의 각 행을 위로 한 칸씩 올리라는 의미입니다. 따라서 전일 종가를 의미하게 됩니다.
○ np.log(df_stock[col] / df_stock[col].shift(-1)) 를 하면, log(금일종가/전일종가)의 뜻이 되므로 바로 일일 로그 수익률이 되는 것입니다.
이 상태에서 df_stock을 출력해보면,
Date KOSPI ... Shinhan_rate KODEX inverse_rate
0 2022.10.13 2162.87 ... -0.001432 0.016698
1 2022.10.12 2202.47 ... 0.008621 -0.009311
2 2022.10.11 2192.07 ... -0.022826 0.021547
3 2022.10.07 2232.84 ... 0.021384 0.003795
4 2022.10.06 2237.86 ... -0.005747 -0.010402
.. ... ... ... ... ...
682 2020.01.08 2151.31 ... -0.017700 0.006996
683 2020.01.07 2175.54 ... 0.015321 -0.010861
684 2020.01.06 2155.07 ... -0.015321 0.007746
685 2020.01.03 2176.46 ... 0.003515 0.000778
686 2020.01.02 2175.17 ... NaN NaN가 되는데요, 제일 끝행의 값이 NaN으로 찍혀있죠. 이것은 데이터 샘플의 끝에 다다라서, 불러올 전일종가가 없기 때문에 발생하는 값 오류입니다. 이러한 값들이 있으면 데이터 분석 시 좋지 않기 때문에 지워줄 필요가 있습니다.
○ dropna() 함수를 쓰면 이러한 NaN 형태의 값들을 없앨 수 있습니다. NaN을 포함하는 열과 행을 Dataframe에서 삭제하게 됩니다.
df_rate = df_stock[[col + '_rate' for col in stock_list]]
# '종목_rate' 이름의 column만 남김
print('Rate DataFrame')
pprint.pprint(df_rate.head())○ df_stock 에 여러 column이 있는데 '종목_rate' 형태의 column 만 남기고 싶으면 위와 같이 하면 됩니다.
○ Dataframe.head()는 Data가 클 때, 위의 5행만 보여주는 함수입니다. 결과를 출력해 보면, 아래와 같습니다.
Rate DataFrame
KOSPI_rate SamsungElec_rate SKT_rate Shinhan_rate KODEX inverse_rate
0 -0.018143 -0.010811 -0.004111 -0.001432 0.016698
1 0.004733 0.007194 0.001026 0.008621 -0.009311
2 -0.018428 -0.014337 -0.030336 -0.022826 0.021547
3 -0.002246 -0.001778 -0.005958 0.021384 0.003795
4 0.010168 0.005343 -0.007890 -0.005747 -0.010402
corr_matrix = df_rate.corr() # 주어진 dataframe의 각 열끼리의 correlation 계산
pd.set_option('display.max_columns', None) # dataframe 출력시 모든 열 다 보이게
pd.options.display.float_format = '{:.2f}'.format # dataframe내 실수값들을 소수2째자리까지 출력
np.set_printoptions(precision=3) # numpy 의 배열을 출력할 때는 소수 세째자리까지 출력
print('\nCorrelation Matrix')
pprint.pprint(corr_matrix)
corr = corr_matrix.to_numpy() #dataframe을 numpy의 배열(array)형태로 변환
print('\nCorrelation Matrix(Array version')
pprint.pprint(corr)○ df_rate.corr() : 각 열 사이의 correlation을 구하고, 이를 상관계수 행렬로 반환해 줍니다. 반환 형식은 <class 'pandas.core.frame.DataFrame'> 입니다. 이는 print(type(corr_matrix))로 알아볼 수 있습니다.
○ dataframe의 사이즈가 크면, 출력시 줄임표로 나오게 됩니다. 이때 모든 열을 보고자 하면, pd.set_option('display.max_columns', None) 의 명령어를 추가하면 됩니다.
○ dataframe을 numpy 라이브러리로 분석을 하려면, 이를 numpy가 인식 가능한 배열 형태로 바꿔줘야 합니다. 이때 쓰는 함수가 df.to_numpy()입니다.
위 code의 결과를 보면,
Correlation Matrix
KOSPI_rate SamsungElec_rate SKT_rate Shinhan_rate \
KOSPI_rate 1.00 0.83 0.14 0.66
SamsungElec_rate 0.83 1.00 0.09 0.51
SKT_rate 0.14 0.09 1.00 0.12
Shinhan_rate 0.66 0.51 0.12 1.00
KODEX inverse_rate -0.98 -0.86 -0.13 -0.64
KODEX inverse_rate
KOSPI_rate -0.98
SamsungElec_rate -0.86
SKT_rate -0.13
Shinhan_rate -0.64
KODEX inverse_rate 1.00
Correlation Matrix(Array version
array([[ 1. , 0.828, 0.142, 0.661, -0.982],
[ 0.828, 1. , 0.091, 0.508, -0.864],
[ 0.142, 0.091, 1. , 0.12 , -0.13 ],
[ 0.661, 0.508, 0.12 , 1. , -0.642],
[-0.982, -0.864, -0.13 , -0.642, 1. ]])입니다. dataframe 형태의 correlation matrix가 마지막 열이 잘려 아래 줄에 나오긴 하지만, max_columns를 display 하는 옵션에 의해 모든 열을 확인할 수 있습니다.
위에서 구한 correlation matrix가 최소한의 상관계수행렬 성질은 만족하고 있는지, 즉 positive definie는 만족하는지 Cholesky분해도 실행해 보겠습니다.
L_scipy = scipy.linalg.cholesky(corr, lower=True) #scipy lib내 choleky 함수로 하삼각행렬 산출
np.set_printoptions(suppress=True) # 과학적표기법을 없앰
print('\nCholesky Decomposition')
pprint.pprint(L_scipy)○ 몇번 다루었지만, 촐레스키 분해는 scipy내의 lianalg.cholesky 로 가능합니다. 자세한 것은 [수학의 재미/행렬 이론] - 촐레스키 분해를 참고하시면 됩니다. 결과를 보면,
Cholesky Decomposition
array([[ 1. , 0. , 0. , 0. , 0. ],
[ 0.828, 0.561, 0. , 0. , 0. ],
[ 0.142, -0.048, 0.989, 0. , 0. ],
[ 0.661, -0.07 , 0.023, 0.746, 0. ],
[-0.982, -0.092, 0.005, 0.001, 0.168]])오류가 나지 않고 잘 분해된 것을 확인할 수 있습니다.
이제 마지막으로 각 종목의 로그수익률간의 관계를 시각화해보죠.
sns.pairplot(df_rate)
plt.show()
sns.heatmap(corr_matrix, annot=True, cmap='Blues', # Red, Yellow, Blue 색상으로 표시
vmin=-1, vmax=1, )
plt.show()아름다운 분석을 위하여 우선 seaborn이라는 통계데이터 시각화 패키지를 import 하여야 합니다.
import seaborn as sns
이 안에 정의된 pairplot을 사용하면, Dataframe 내의 각 column 간 관계를 분산 표(scatter)나 히스토그램(histogram) 형식으로 보여줍니다. 결과를 보면,
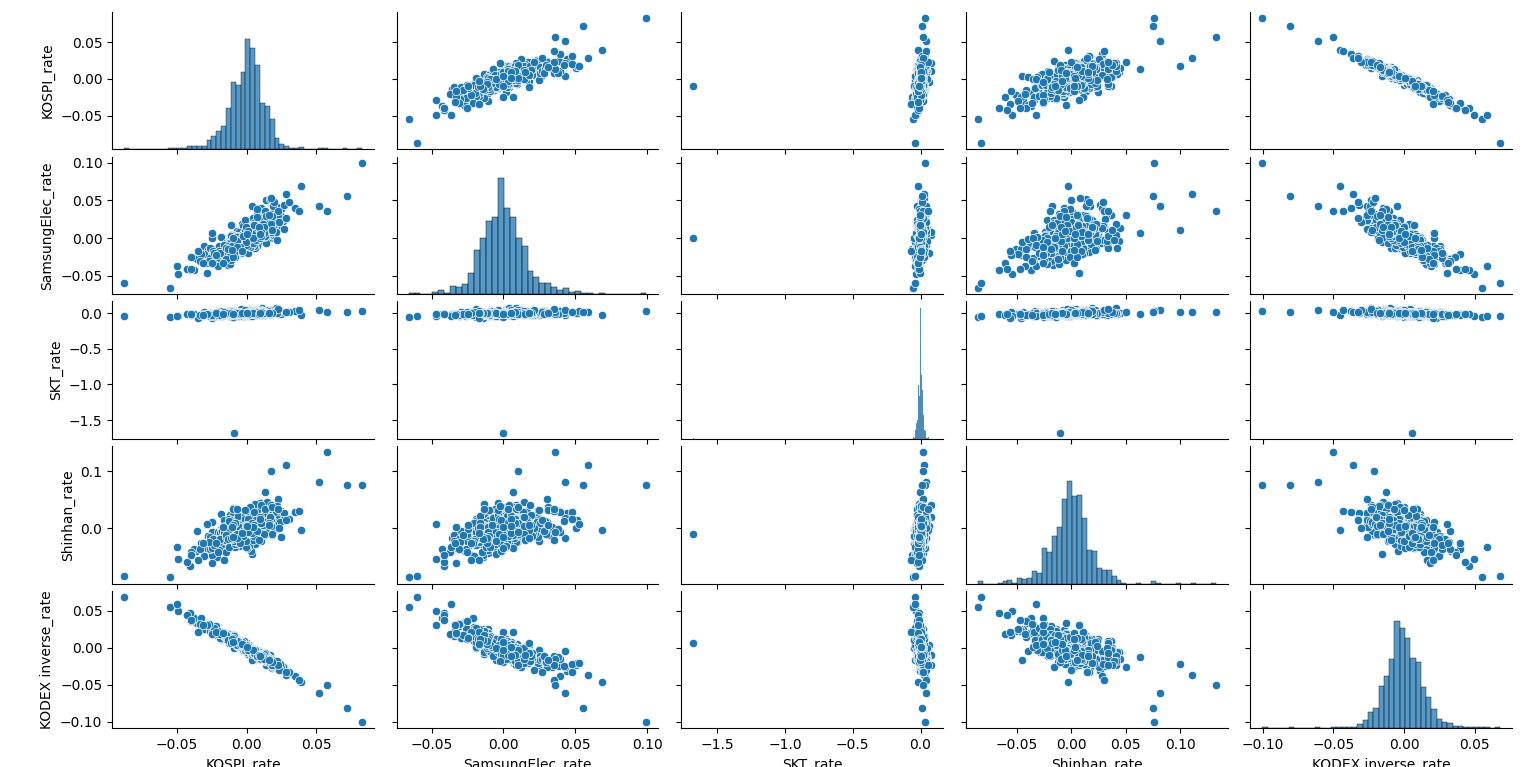
각 종목간 관계 그래프가 나오게 되죠. 또한 heatmap을 사용하여 상관계수 행렬을 표현해 볼 수 있습니다. 각 원소의 크기에 따라 색을 달리하여 보여주는 기법입니다.
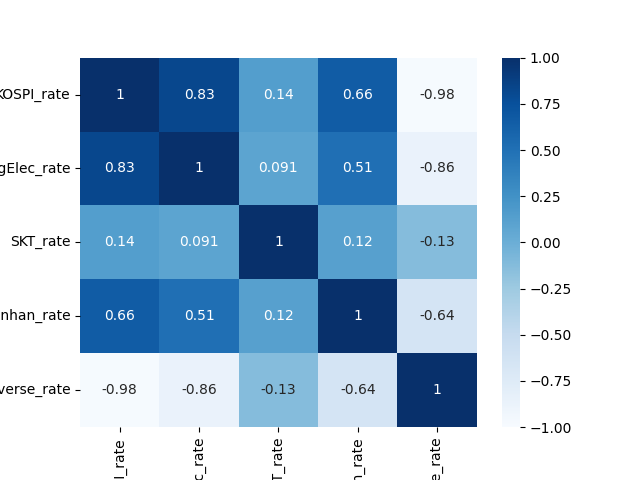
당연한 얘기지만, KOSPI 와 삼성전자, SK텔레콤, 신한지주는 양의 상관관계를 보입니다. 특히, 삼성전자는 KOSPI의 절대적 비중을 차지하고 있는 대장이기에 그 상관계수가 엄청 크겠죠. 대표적 금융주 중 하나인 신한지주 역시 상관관계가 높으나 삼성전자보다는 작습니다. 반면, 경기방어주에 고배당으로 알려진 SK텔레콤은 양의 상관관계이긴 하지만, 거의 KOSPI의 움직임과 독립적이라는 것을 알 수 있습니다.(상관계수 0.12)
마지막으로 KODEX 인버스는 KOSPI의 수익률과 부호가 반대이므로 당연히 상관계수가 -1일 거라는 생각이 들고, 실제적으로도 -0.98을 얻었습니다.
'금융공학' 카테고리의 다른 글
| 워스트 퍼포머(worst performer)의 분포 #1 (0) | 2022.10.26 |
|---|---|
| 자산의 퍼포먼스(performance)와 워스트포퍼머(worst performer) (0) | 2022.10.24 |
| 상관관계가 있는 세 자산이 움직이는 모습은? (0) | 2022.10.14 |
| 상관관계가 있는 여러 자산이 움직이는 모습 (0) | 2022.10.13 |
| 상관관계가 있는 두 자산이 움직이는 모습은? (0) | 2022.09.30 |



댓글