이 글은
2022.10.24 - [금융공학] - 자산의 퍼포먼스(performance)와 워스트포퍼머(worst performer)
자산의 퍼포먼스(performance)와 워스트포퍼머(worst performer)
이번 글에서는 지수나 주식 같은 자산의 퍼포먼스(performance)가 무엇인지를 정의해보고, 이를 이용하여 두 개 이상 자산의 워스트 포퍼머(worst performer)의 개념이 무엇인지 알아보겠습니다. 예를
sine-qua-none.tistory.com
에서 이어집니다. 지난 글에서는 여러 개의 주식이 주어져 있을 때,
○ 각 주식의 퍼포먼스(performance)를 정의하고
○ 이 중, 가장 성과가 떨어지는 워스트 퍼포머(worst performer)라는 시계열을 정의해 보았습니다.
워스트 포퍼머는 금융상품의 기초자산으로 널리 쓰이고, 특히 ELS 등 파생상품의 설계에 긴요하게 쓰이는 개념입니다. 따라서 워스트 포퍼머를 잘 이해하는 것이 필요합니다.

우선, 주식의 갯수는 2개, 모든 주식의 움직임을 GBM으로 가정하겠습니다. 즉, 주식 X1,X2 에 대해
dXi(t)/Xi(t)=(r−qi)dt+σidWi(t) , i=1,2
라 가정해보죠. 그리고 두 자산의 로그수익률의 상관계수를 ρ라 합시다. 즉,
dW1dW2=ρdt
인 상황입니다([금융공학] - 상관관계를 보이는 두 자산의 움직임 모델을 참고해 보면 됩니다.)
한 가지 중요한 점이 원래 주식 모델이 GBM이면, 그것의 퍼포먼스도 GBM이죠. 당연한 것이, 퍼포먼스라는 것은 원래 주가를 어떤 기준가로 나눈 것에 불과하기 때문입니다. 예를 들어 X(t)라는 주식이 GBM dX(t)/X(t)=μdt+σdWt를 따른다면, 기준점 X(0)로 나눈 새로운 프로세스
x(t)=X(t)X(0) 의 다이나믹은
dx(t)/x(t)=dX(t)X(0)/X(t)X(0)=dX(t)/X(t)=μdt+σdWt
처럼 원래 주식과 동일한 GBM 이 됩니다.
따라서 우리는 식(1)의 Xi들을 주식이 아닌 퍼포먼스라 생각해도 무방합니다.
워스트 퍼포먼스의 분포를 구해보자
식(1)에서 정의한 두 퍼포먼스 X1,X2의 워스트 포퍼머의 분포를 구해볼까 합니다.
1 변수 표준 정규분포의 누적분포 함수(cdf)를 Φ(⋅), 이변량 표준정규분포의 누적분포함수(cdf)를 Φ2(⋅;ρ) 라 합시다. 이와 같이 쓰는 이유는 표준 정규분포를 가정하므로 평균은 모두 0, 분산은 1인 상황이라 누적분포함수의 모양은 두 변수의 상관계수에만 의존하게 되겠죠.
식(1)의 X1(t),X2(t)의 기준시점에서의 퍼포먼스를 각각 x1,x2라 하면,
Xi(t)=xiexp((r−q−12σ2i)t+σiWi(t)) , i=1,2
가 됩니다.
(시점 t=0에서 따지면 xi들은 무조건 1인데요, 위에서는 특정 시점의 퍼포먼스 초기값과 잔존만기를 생각하여 xi라는 값으로 살려둔 것입니다.)
많이 다루었다시피 i=1,2에 대해 , Wi(t)=√tzi , zi∼N(0,1) 이고, 상관계수를 도입하면
Corr(z1,z2)=ρ
입니다.(서서히 이변량 표준 정규분포를 쓸 수 있는 모습이 되가죠?)
간단한 표기를 위해
μi:=r−q−12σ2i , i=1,2
라 정의합니다. 그러면 최종적으로
Xi(t)=xiexp(μit+σi√tzi) , i=1,2
이고 Corr(z1,z2)=ρ입니다.
드디어 워스트 퍼포머의 분포를 구할 준비가 끝났습니다. 워스트 퍼포머를 wp(t):=min(X1(t),X2(t)) 라 합시다. 우리의 목적은 실수 K에 대해
P(wp(t)≤K)
의 값을 구하는 것입니다.
P(wp(t)≥K)=P(min(X1(t),X2(t))≥K)=P(X1(t)≥K and X2(t)≥K)=P(ln(X1(t))≥lnK and ln(X2(t))≥lnK)
두 번째 등식은 min(x,y)≥K⇔(x≥K)∩(y≥K) 의 성질이 쓰였고, 세 번째 등식은 x≥K⇔lnx≥lnK의 성질이 쓰였습니다.
식(3)을 이어나가기 위해, 식(2)을 대입하면
P(ln(X1(t))≥lnK and ln(X2(t))≥lnK)=P(z1≥ln(K/x1)−μ1tσ1√t,z2≥ln(K/x2)−μ2tσ2√t)=P(z1≥α1,z2≥α2)
입니다. 여기서 편의를 위해
αi=ln(K/xi)−μitσi√t , i=1,2 라 정의했습니다.
이제 식(4)만 구하면 됩니다. 식(4)에서 확률을 구하는 영역은 아래 그림(파란색 영역)입니다.
이는 여집합을 생각하여 아래 그림처럼 구할 수 있죠(오렌지색 영역)
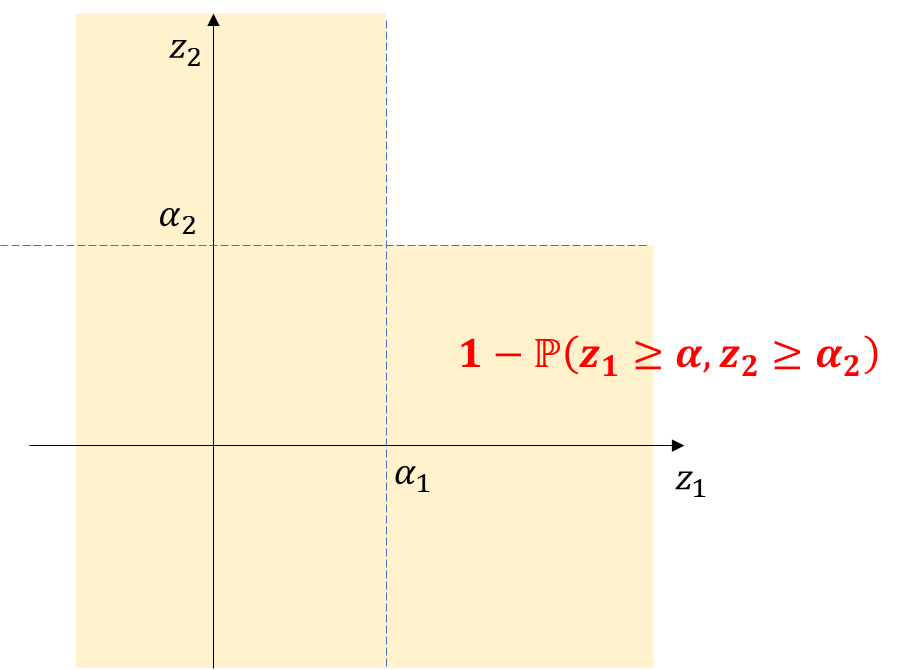
이 영역은 다시 아래 두 영역을 합쳐준 뒤(회색 영역 2개)

겹치는 부분인 아래 그림의 녹색 영역을 빼주면 됩니다.
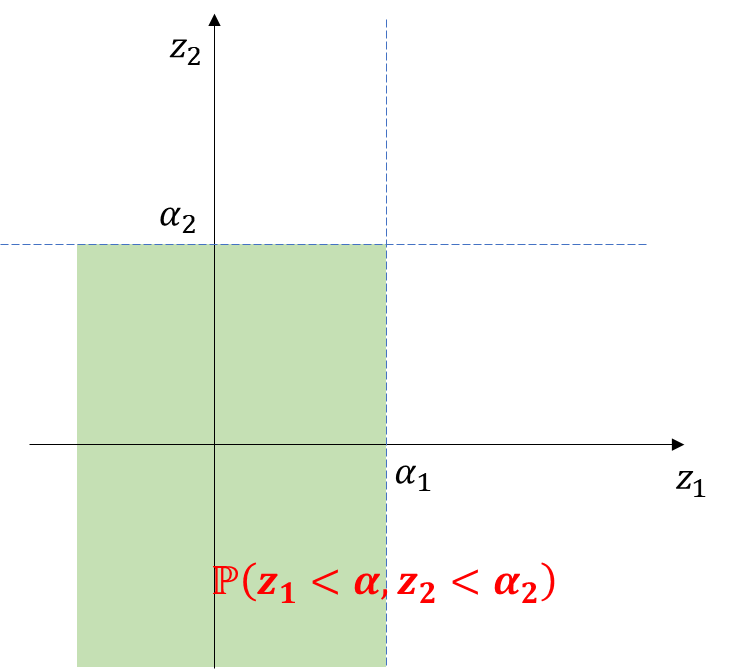
그림으로 이해한 바를 수식으로 써보면,
P(z1≥α1,z2≥α2)=1−[P(z1≤α1)+P(z2≤α2)−P(z1≤α1,z2≤α2)]
입니다.
그런데 위 식 우변의 등장한 세 개의 항은 각각 무엇일까요? marginal distribution을 생각해보면 바로
P(z1≤α1)=Φ(α1)P(z2≤α2)=Φ(α2)P(z1≤α1,z2≤α2)=Φ2(α1,α2;ρ)
이죠. 결론적으로 식(3)~(6)을 쭉 이어 보면
P(wp(t)≥K)=1−Φ(α1)−Φ(α2)+Φ2(α1,α2;ρ)
를 얻습니다.
wp(t)의 누적분포함수(cdf)를 Fwp(K) 라 하면, Fwp(K)=P(wp(t)≤K) 이므로 최종적으로 아래와 같이 정리할 수 있습니다.
기초자산 X1,X2 의 워스트포퍼머는 다음과 같은 누적분포함수 Fwp(K)를 따른다.
Fwp(K)=Φ(α1)+Φ(α2)−Φ2(α1,α2;ρ)
여기서
αi=ln(K/xi)−μitσi√t , i=1,2
이다.
다음 글에서 이 식이 맞는지를 이 식으로 직접 구한 결과와 몬테카를로 시뮬레이션 방법으로 구한 결과를 비교하여 서로 크로스 체킹 하여보겠습니다.
'금융공학' 카테고리의 다른 글
| 스텝다운 ELS (0) | 2022.11.16 |
|---|---|
| 워스트 퍼포머(worst performer)의 분포 #2 : Python Code (0) | 2022.10.26 |
| 자산의 퍼포먼스(performance)와 워스트포퍼머(worst performer) (0) | 2022.10.24 |
| 상관관계가 있는 실제 주가의 움직임 (0) | 2022.10.21 |
| 상관관계가 있는 세 자산이 움직이는 모습은? (0) | 2022.10.14 |



댓글